Jean-Vincent Loddo
Un Site Web pour la recherche en sciences humaines
La naissance du World Wide Web au CERN, le Centre Européen de Recherche Nucléaire, en 1989 sur Internet, peut être considérée comme la plus grande révolution dans le domaine de la communication et de l'édition de l'information après l'apparition de l'imprimerie. Le développement simultané du matériel et du logiciel informatique de ces dernières années rend aujourd'hui possible à n'importe quel utilisateur, entreprise ou organisme de créer son propre site Web sans grandes difficultés techniques et pour un investissement économique modeste. Désormais, les fournisseurs d'accès Internet (ISP) proposent, pour des prix raisonnables, voire gratuitement, des services d'hébergement de site Web avec, le plus souvent, des fonctionnalités très avancées d'un point de vue technique (serveur de bases de données, langages de scripts CGI, logiciels de maintenance à distance, etc.).
Grâce aux logiciels d'édition actuellement disponibles sur le marché, il n'est plus nécessaire de connaître le langage HTML (Hypertext Markup Language) pour décrire et structurer les différents objets (textes, liens, tableaux, images, vidéos ou sons) qui constituent un hypertexte, mais il suffit de quelques clics de souris pour mettre en place ces éléments de la façon dont ils apparaîtront sur l'écran des visiteurs du site. Cependant, l'apport des informaticiens ne peut être facilement remplacé par de tels logiciels lorsque l'hypertexte est dynamique, c'est-à-dire lorsque le contenu des pages est en perpétuelle mutation et correspond au contenu d'une base de données en évolution. Il y aura alors une série de problèmes qui demandera un niveau de compétence supérieur, d'une part pour concevoir et gérer la base de données, d'autre part pour intégrer les données dans les pages générées dynamiquement. Nous allons donc prendre l'HyperNietzsche comme modèle pour discuter et approfondir les problèmes et les difficultés impliquées par un projet de ce genre.
Les composants logiciels
Dans le jargon des informaticiens un serveur était, à l'origine, quand les ordinateurs n'étaient pas aussi efficaces qu'aujourd'hui, une machine destinée à une tâche spéciale, par exemple celle de répondre sur l'Internet aux requêtes des butineurs http (Netscape, Mosaic, Internet Explorer, etc.), appelés clients du serveur. Avec les performances croissantes des couches matérielles[1], l'arrivée des systèmes d'exploitation multitâches et des technologies comme le multithreading[2], un seul ordinateur peut aujourd'hui héberger plusieurs programmes et remplir ainsi plusieurs fonctions en même temps. La notion de serveur ne correspond plus à une machine mais plutôt à un logiciel à l'écoute des requêtes des clients, qui réside sur une machine sur laquelle peuvent s'exécuter aussi d'autres logiciels remplissant d'autres services, donc d'autres serveurs.
Un système qui accomplit les fonctions requises à l'HyperNietzsche doit être au moins constitué de deux serveurs – le serveur http et le serveur de bases de données –, puis d'un système d'exploitation multitâches capable d'héberger les deux serveurs et de gérer le matériel (processeurs, mémoires, disques) d'une façon efficace et fiable.
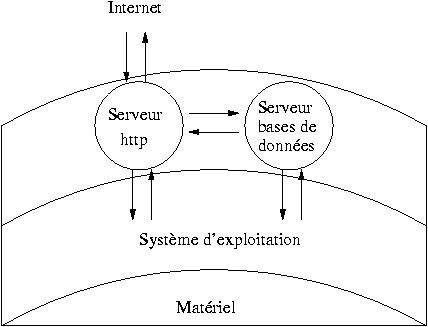
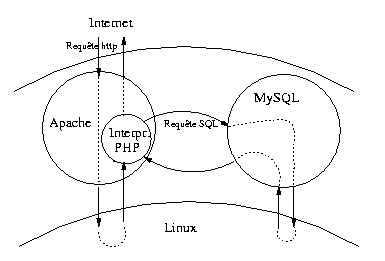
Malgré les nombreuses possibilités existantes, le choix de l'architecture matérielle et logicielle n'a pas été pour nous un problème épineux. En effet, il existe désormais une solution optimale d'un point de vue économique et technique, provenant du monde du logiciel libre, et qui est composé de Linux comme système d'exploitation, d’Apache comme serveur http, de MySQL comme serveur de bases de données et, enfin, de PHP comme module additionnel d’Apache pour la communication entre les deux serveurs et la génération de pages dynamiques. Pour une telle couche logicielle, le matériel ne doit pas nécessairement être des plus coûteux et et des plus performants : un modeste PC (Personal Computer) ou un réseau de PC, ordinateurs désormais de moindre coût, permettent d'exécuter efficacement Linux et les autres logiciels de support.
Le système d'exploitation GNU Linux
Conçu au départ comme un clone Unix pour PC en 1991 par Linus Torvald, un étudiant de l'Université de Helsinki, en Finlande, et ensuite développé par de nombreux programmeurs grâce au réseau mondial Internet, Linux est rapidement devenu l’un des systèmes d'exploitation les plus populaires au monde. Son succès s'explique facilement par sa structure propre bien conçue, sans doute due à la formation académique de son créateur, par son code source accessible et modifiable, en un mot libre (en anglais open), et aussi par une sorte de déontologie informatique selon laquelle toutes les normes et les standards (IEEE POSIX.1, System V, BSD, protocoles de l'Internet etc) sont rigoureusement respectés. Mais le trait le plus séduisant de Linux est certainement sa gratuité. Cet aspect accompagne son haut niveau technique et le rend quasiment imbattable vis-à-vis de ses concurrents commerciaux.
Il est nécessaire de préciser que sous le nom Linux se cache souvent non seulement le cœur ou noyau (kernel) d'un système d'exploitation, mais aussi toute une panoplie de logiciels qui constitue une imposante boîte à outils pour l'exploitation de la machine. Ces logiciels sont issus du mouvement GNU (acronyme récursif Gnu is Not Unix) créé en 1984 par Richard Stallman, à l'époque chercheur au Laboratoire d'Intelligence Artificielle du MIT. Ils représentent une partie très importante du système, un trousseau sans lequel le noyau Linux lui-même n'aurait pas pu être développé. Comme tous les logiciels GNU, Linux est utilisable sous licence General Public License GNU (GPL) pour laquelle la libre copie, modification et redistribution du programme est permise mais à condition de toujours livrer les sources et de ne pas empêcher les autres de faire de même.
D'un point de vue technique, les caractéristiques les plus marquantes de Linux sont la portabilité du code, qui fait que le noyau peut s'exécuter sur différentes architectures (PC, Machintosh, SPARC, entre autres), un système de fichiers (ext2) performant et fiable, la prise en compte de la quasi-totalité des autres systèmes de fichiers du marché (DOS, VFAT, Apple Macintosh, NTFS, OS/2 HPFS, etc.), l'implantation complète de la couche réseau TCP/IP, la pagination de la mémoire vive, la mémoire virtuelle (espace de swap), les librairies dynamiques partagées et l'optimisation des accès aux disques (cache).
Le serveur http Apache
Disponible en licence GPL pour différentes plates-formes, Apache est à l'heure actuelle le serveur http (ou serveur web) le plus employé au monde et représente l’un des chevaux de bataille du mouvement pour le logiciel libre. Le projet Apache a été développé sur la base d'un des premiers serveur http, le NCSA httpd, construit par le National Center for Supercomputing Applications, un établissement public américain qui rendit disponible le code source du logiciel, ce dernier étant développé grâce à l'argent des contribuables.
Ce logiciel conjugue plusieurs qualités qu'on demande à un serveur http. D'abord, il est capable d'exploiter les caractéristiques multitâches d'un système d'exploitation comme Linux pour gérer plusieurs requêtes à la fois et, aussi, pour permettre à un administrateur de maintenir le système sans interrompre le service. Ensuite, il peut négocier avec le client un style ou une langue pour les réponses, un format de fichier pour les images (jpeg, gif, tiff, etc.) ou pour les textes (dvi, Postscript, pdf, etc.). Enfin, en ce qui concerne la sécurité, il est capable d’authentifier les clients pour permettre certains services spéciaux. N'importe quel serveur http est le douanier du système pour les clients provenant d'Internet et, par conséquent, ouvre une porte qui peut être exploitée par des pirates informatiques. Le code écrit par les programmeurs d'Apache envisage, dans les limites du possible, les violations d'un système hébergeant le logiciel. De plus, ces mêmes programmeurs, très sensibles à la question, réagissent promptement et proposent les corrections du code (patch) dès qu’un trou de sécurité potentiellement exploitable est découvert et signalé aux responsables du projet.
Le serveur de bases de données MySQL
Il s'avère qu’Apache n'a pas de véritables concurrents dans le contexte du logiciel libre. En revanche, on ne peut pas en dire autant des systèmes de gestion de bases de données (SGBD) qui sont nombreux et de bonne qualité. À l'heure actuelle, les principaux acteurs sont PostgreSQL[3] et MySQL[4], tous deux fondés sur le modèle relationnel, le premier complètement libre et gratuit, le second libre mais uniquement gratuit pour les systèmes d'exploitation non Microsoft, comme Linux, FreeBSD ou OS/2.
Moins puissant que son rival Postgres, MySQL présente toutefois, dans sa simplicité, des atouts intéressants. On relève son efficacité et son adoption du langage SQL (Structured Query Language) pour exprimer les requêtes au serveur. Toutes les opérations de création, modification, insertion, élimination de la structure des données (les tables) ou des données elles-mêmes (les enregistrements) se font par le biais de requêtes exprimées en SQL, un langage de haut niveau, largement standardisé depuis sa conception dans les années '70, qui permet d’indiquer les données que l'on souhaite extraire sans besoin de spécifier comment y accéder : le système se charge de les rechercher. L'existence d'un certain nombre de logiciels à interface graphique pour définir et gérer une base de données MySQL d'une façon très conviviale, peut voiler à l'utilisateur la technologie sous-jacente. Il s'agit tout simplement de programmes d'interface qui traduisent les clics de souris en requêtes SQL expédiées et traitées par le serveur MySQL, que l'utilisateur ne voit pas et dont il n’a probablement pas conscience. Parmi ces programmes, le précieux PHPMyAdministrator, écrit dans le langage PHP que nous allons traiter par la suite, mérite une attention toute particulière puisqu’il permet de gérer une base de données MySQL aisément et à distance via le réseau Internet à l’aide d’un simple butineur http.
Le module PHP pour Apache
Un site Internet est qualifié de dynamique lorsque le contenu, qui est du code HTML, est le résultat d'un calcul effectué à la volée par le serveur http. En revanche, quand le site est statique, le contenu est stocké une fois pour toutes dans des fichiers. À l'heure actuelle, les deux solutions les plus répandues pour construire un site dynamique sont la technologie CGI (Common Gateway Interface) et les langages HTML-embedded dont fait partie PHP. La première prévoit que le serveur http active, pour chaque requête de page dynamique, un autre programme dont la sortie (l'output), au format HTML, sera canalisé vers le client. L'avantage de cette approche est que les programmes générateurs du HTML seront indépendants du serveur http et pourront être écrits dans le langage préféré du programmeur. Le choix d'un langage compilé (C, Pascal, etc.) et pas celui d'un langage interprété (Perl, Python, etc.) favorisera l'efficacité des réponses, ce qui peut représenter un deuxième avantage de cette technique. Mais l'inconvénient principal est qu'une partie du code HTML que le programme produit pendant son exécution se trouve discrètement caché à l'intérieur des sources du programme, ce qui rend souvent délicates les modifications du contenu du site.
Face à cet inconvénient, c'est la deuxième solution, celle d'un langage HTML-embedded, qui paraît être la plus souple et avantageuse. En premier lieu, le rôle d'un serveur http, comme Apache, est celui de traduire une requête provenant d'Internet dans l'adresse du fichier de type HTML correspondant. Ensuite il se doit d'envoyer ce fichier au client en suivant le protocole http. Cette solution consiste donc à rendre le serveur http capable d'interpréter les fichiers juste avant leur envoi aux clients. Ainsi, il existe un module qui augmente les fonctionnalités du logiciel Apache en lui donnant la possibilité d'interpréter les fichiers composés d'instructions PHP, un langage de programmation impératif classique inspiré des langages C, Perl et Java. Pour exploiter cette nouvelle fonctionnalité, les fichiers se trouvant sur le serveur pourront alors être composés de parties écrites en HTML et d'autres parties écrites en PHP. Les parties en PHP, éventuellement présentes, seront interprétées par Apache lui-même pour composer (on dira "dynamiquement") un fichier qui, finalement, sera de type HTML et pourra être visualisé par le logiciel de navigation du client.
Ce principe de fonctionnement facilite la construction du site. Les graphistes s'occuperont des parties HTML en utilisant éventuellement des logiciels d'édition pour soigner le style de présentation des contenus. Par ailleurs, les programmeurs pourront modifier les contenus en intervenant sur les parties PHP des mêmes fichiers.
Le module PHP pour Apache est sous licence GPL et il est disponible, avec ses manuels, sur le site Internet de ses créateurs[5]. D'un point de vue technique, les traits les plus marquants de ce langage sont sa ressemblance avec le langage C d'un côté, et sa large bibliothèque de fonctions d'un autre. Parmi ces multiples fonctions, on en distingue en particulier, celles liées à l'envoi des requêtes à un serveur de bases de données, tel qu’Oracle, Sybase, MySQL, ODBC, PostgreSQL, Informix, FilePro.
|
|
L'interaction entre philosophes et informaticiens
La première phase d'un projet comme l'HyperNietzsche est naturellement celle dans laquelle les philosophes et les informaticiens discutent de la structure du site et, en particulier, de l'ensemble des données sur lesquelles il s'appuie.
Deux types fondamentaux de données sont concernés dans l'HyperNietzsche : les données relatives aux matériaux et celles relatives aux contributions. Du premier type font partie les œuvres et les manuscrits de Nietzsche, les lettres, les livres de la bibliothèque de Nietzsche et leur reçus, mais aussi des parties (logiques) ou portions (physiques) des précédents comme les aphorismes ou chapitres d'une oeuvre, les pages d'une oeuvre, d'une lettre ou d'un livre, les fragments d'une page, etc. Du second type font partie les essais, les commentaires, les chemins (génétiques, thématiques ou chronologiques), les transcriptions (linéarisées ou diplomatiques, interactives ou autres), les bibliographies, les traductions et les numérisations.
La base de données des matériaux
La base de données des matériaux, dénommée hn_materiaux, est constituée de plusieurs tables. Chaque matériau a un code unique, la clef_materiau, qui l'identifie dans l'ensemble de tous les matériaux. La table principale, appelée materiaux, enregistre la relation entre ce code universel et le type de matériau dont il s'agit (oeuvre, manuscrit, lettres, etc) et renvoie ainsi à la table correspondante dans la même base de données.
CREATE TABLE hn_materiaux.materiaux (
clef_materiau INTEGER NOT NULL AUTO_INCREMENT,
nom_table ENUM( "materiaux_lettres",
"materiaux_lettres_pages",
"materiaux_livres",
"materiaux_manuscripts",
"materiaux_manuscripts_pages",
"materiaux_oeuvres",
"materiaux_oeuvres_aphorismes",
"materiaux_oeuvres_chapitres",
"materiaux_oeuvres_pages",
"materiaux_recus",
"materiaux_recus_entrees" ),
clef_locale INTEGER NOT NULL,
PRIMARY KEY ( clef_materiau ),
UNIQUE ( nom_table, clef_locale )
);
Les autres tables de la base hn_materiaux ont donc une structure spécifique au type de matériau qu’elles représentent. Par exemple, la table des oeuvres de Nietzsche est constituée par des attributs (ou champs) qui enregistrent, pour chaque oeuvre, son sigle, son entrée bibliographique (la référence dans l'HyperNietsche), les Archives où elle est conservée, sa cote aux Archives et, enfin, si elle a été imprimée et diffusée (ID), imprimée mais non diffusé (IND) ou non imprimée ni diffusée (NIND).
CREATE TABLE hn_materiaux.materiaux_oeuvres (
oeuvre INTEGER NOT NULL AUTO_INCREMENT, # clef locale
sigle VARCHAR(20) NOT NULL,
code_biblio_hn INTEGER NOT NULL,
archive INTEGER,
collocation VARCHAR(30),
type ENUM("ID","IND","NIND"),
PRIMARY KEY ( oeuvre ),
UNIQUE ( code_biblio_hn ),
INDEX ( sigle )
);
La table des lettres constitue un autre exemple. Les informations spécifiques sont ici la date (autographe) d'écriture, l'expéditeur, le destinataire et, comme pour les oeuvres, les Archives où elle est conservée et la cote.
CREATE TABLE hn_materiaux.materiaux_lettres (
lettre INTEGER NOT NULL AUTO_INCREMENT, # clef locale
date_autographe DATE,
expediteur INTEGER NOT NULL,
destinataire INTEGER NOT NULL,
archive INTEGER,
collocation VARCHAR(30),
PRIMARY KEY ( lettre ),
INDEX ( expediteur ),
INDEX ( destinataire ),
INDEX ( archive )
);
Le cas des matériaux contenus dans d'autres matériaux, comme les chapitres ou les aphorisme d'une oeuvre, est plus délicat. Pour établir le lien entre le matériau contenu (le chapitre) et le matériau contenant (l'oeuvre), on enregistrera le code de ce dernier dans la table du matériau contenu. Dans l'exemple suivant, celui de la table des chapitres des oeuvres, l'attribut oeuvre établit ce lien. Un autre attribut, qu'on appellera numerotation, permet de définir un ordre parmi les portions contenues dans un même matériau. Ainsi, d'une oeuvre spécifique nous pourrons retrouver les données du premier chapitre, du deuxième et ainsi de suite.
CREATE TABLE hn_materiaux.materiaux_oeuvres_chapitres (
chapitre INTEGER NOT NULL AUTO_INCREMENT, # clef locale
oeuvre INTEGER NOT NULL,
numerotation INTEGER,
titre VARCHAR(255),
PRIMARY KEY (chapitre),
UNIQUE ( oeuvre, numerotation ),
INDEX ( oeuvre )
);
Dans cette base de données, les matériaux sont décrits mais n'ont pas de représentation digitale. La raison en est simple : toute représentation digitale d'un matériau, par exemple un fichier html contenant l'oeuvre Der Wanderer und sein Schatten, est le résultat d'un travail rendu par un ou plusieurs auteurs. Cet apport, qu'on appellera numerisation, sera considéré comme une contribution au développement de l'HyperNietzsche et sera enregistré dans la base de données correspondante.
La base de données des contributions
La base de données des matériaux est distribuées selon des tables spécifiques aux divers types de matériaux existants. En revanche, toutes les contributions, malgré leurs différences, sont enregistrées dans une seule table, appelée contributions, de la base de données hn_contributions. Ce choix est dû à la nature récursive du type de données des contributions. Une traduction, par exemple, est une contribution qui peut avoir comme objet un essai, qui est lui-même une contribution. Aussi, les numérisations des essais, des commentaires, des chemins etc., sont des contributions qui font référence à d'autres contributions. La définition d'une contribution a donc un caractère récursif qui compliquerait la reconstitution des données distribuées sur plusieurs tables. De là le choix de regrouper toutes les contributions dans une seule table, avec plusieurs attributs, éventuellement significatifs en fonction du type de contribution concernée. Par exemple, l'attribut fichier, qui indique l’adresse où est stocké le fichier correspondant à la contribution concernée, sera significatif seulement dans le cas d'une numérisation (d'un matériau ou d'une autre contribution).
CREATE TABLE hn_materiaux.contributions (
clef_contribution INTEGER NOT NULL auto_increment,
date_presentation DATE,
date_acceptation date,
date_disponibilite_online date,
type
ENUM('bibliographie',
'chemin genetique',
'chemin thematique',
'chemin chronologique',
'commentaire',
'essai',
'transcription diplomatique',
'transcription linearise',
'traduction contribution',
'traduction matériau',
'numerisation matériau',
'numerisation contribution')
NOT NULL,
contribution_objet INTEGER,
materiau_objet INTEGER,
langue INTEGER,
titre VARCHAR(255),
abstract text,
long_abstract text,
description text,
presentation text,
commentaire_des_auteurs text,
format enum('html','ps','pdf','txt','gif','jpeg'),
couleur enum('couleur','noir et blanc'),
dpi INTEGER UNSIGNED,
fichier INTEGER,
contribution_precedente INTEGER,
contribution_suivante INTEGER,
PRIMARY KEY (clef_contribution),
KEY contribution_objet (contribution_objet),
KEY materiau_objet (materiau_objet),
KEY type_langue (type, langue),
KEY contribution_objet_langue (contribution_objet, langue),
KEY materiau_objet_langue (materiau_objet, langue),
KEY format (format),
KEY fichier (fichier),
KEY contribution_precedente
(contribution_precedente, contribution_suivante)
);
Un contribution peut avoir un ou plusieurs auteurs. Pour ne pas limiter a priori le nombre d'auteurs possibles et, surtout, pour optimiser les recherches des auteurs d'un certain type de contribution, il est préférable de définir une table à part qu'on appellera contributions_auteurs.
CREATE TABLE hn_materiaux.contributions_auteurs (
clef_contribution INTEGER NOT NULL,
clef_annuaire INTEGER NOT NULL,
PRIMARY KEY (clef_contribution, clef_annuaire),
KEY clef_contribution (clef_contribution),
KEY auteur (clef_annuaire)
);
Pour gérer l'allocation des fichiers, qui pourront être déposés sur le disque local ou sur un serveur ftp du réseau local ou sur l'Internet, nous aurons une table d'allocation à la mode des FAT (File Allocation Table) des systèmes d'exploitation.
CREATE TABLE hn_fichiers.fat (
fichier INTEGER NOT NULL AUTO_INCREMENT,
allocation VARCHAR(255) NOT NULL,
KEY fichier (fichier),
UNIQUE allocation (allocation)
);
La maquette en html et sa transformation dynamique
Le choix d'un langage HTML-embedded comme PHP est une solution qui présente un avantage peut-être inattendu dans le développement d'un site web. Les philosophes, probablement novices dans l'art de la programmation, pourront toutefois réaliser, à l'aide d'un logiciel graphique tel que GoLive, Dreamweaver, PageMill, etc., la partie HTML des pages dynamiques. Le résultat d'un tel travail sera à la fois un prototype du site et, en même temps, une spécification formelle de ce que l'on s'attend du site. Le programmeur devra alors prendre le relais pour ajouter le code PHP générateur des parties dynamiques.
Supposons par exemple que nous visualisons le cadre de mise en contexte hypertextuelle concernant l’œuvre Der Wanderer und sein Schatten (Le voyageur et son ombre) et accédons à la liste des contributions relatives à cette œuvre. Le maquettiste aura dessiné une page de ce type :
Le programmeur ira donc fouiller dans le code HTML correspondant (que nous présentons ici sous forme quelque peu abrégée) pour cerner les parties devant être générées dynamiquement et pour y insérer le code PHP adéquat.
|
|
<html> <head> <meta http-equiv="content-type" content="text/html;charset=iso-8859-1"> <title>Liste des contributions</title> <base target="_blank"> </head> <body background="/images/fonds/fond.gif"> <center><h3><br>Contributions <hr width="70%"></h3></center> <div align="left">
<h4>Transcriptions</h4>
<table border="0" cellspacing="2" cellpadding="0"> <tr valign=top> <td><img src=/images/boules/contributions.gif width="14" height="14" naturalsizeflag="0"></td> <td> <font size="3">Paolo<a href="/contextes/auteurs/cadre_auteurs.php3?lang=33&auteur=10" target="_blank"> D'iorio</a>, Jean<a href="/contextes/auteurs/cadre_auteurs.php3?lang=33&auteur=20" target="_blank"> Loddo</a>, <a href="/contextes/contributions/cadre_contributions.php3?lang=33&materiau=1&transcription=5"> diplomatique</a></td></font></tr></table>
<h4>Chemins génétiques</h4> ... <h4>Chemins thématiques</h4> ... <h4>Commentaires</h4> ... <h4>Essais</h4> ... <h4>Traductions</h4> ... </body> </html>
|
Dans cet exemple, les tables qui suivent les titres de niveau 4 (<h4>Transcriptions</h4>, <h4>Chemins génétiques</h4> etc.) doivent être remplacées par un code PHP qui interroge la base de données pour récupérer les contributions effectivement associées au matériau mis en contexte. Le code PHP est reconnaissable par le fait qu’il est délimité par des balises « <? » et « ?> ».
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=iso-8859-1">
<title>Liste des contributions</title>
<base target="_blank">
</head>
<body background="/images/fonds/fond.gif">
<center><h3><br>Contributions <hr width="70%"></h3></center>
<div align="left">
<h4>Transcriptions</h4>
<? lister_transcriptions_de_materiau ($clef_materiau); ?>
<h4>Chemins génétiques</h4>
<? lister_chemins_de_materiau ($clef_materiau,'genetique'); ?>
<h4>Chemins thématiques</h4>
<? lister_chemins_de_materiau ($clef_materiau,'thematique'); ?>
<h4>Chemins chronologiques</h4>
<? lister_chemins_de_materiau ($clef_materiau,'chronologique'); ?>
<h4>Commentaires</h4>
<? lister_commentaires_de_materiau ($clef_materiau); ?>
<h4>Essais</h4>
<? lister_essais_de_materiau ($clef_materiau); ?>
<h4>Traductions</h4>
<? lister_traductions_de_materiau ($clef_materiau); ?>
</body>
</html>
Pour expliquer davantage le fonctionnement du code PHP, prenons par exemple la fonction lister_transcriptions_de_materiau() écrite expressément pour cette tâche. Elle interroge le serveur MySQL par une requête SQL avec l’appel de la fonction standard mysql_query().
function lister_transcriptions_de_materiau (
$clef_materiau,
$type = "", // "linearise", "diplomatique" sinon toutes
$src_img = "/images/boules/contributions.gif",
$href_base="/contextes/contributions/cadre_contributions.php3",
$href_base_auteur="/contextes/auteurs/cadre_auteurs.php3"
)
{
$connection = mysql_connect("localhost","httpd","");
if ($type=="linearise")
$suffix = " and type='transcription linearise'";
if ($type=="diplomatique")
$suffix = " and type='transcription diplomatique'";
$result = mysql_query("select clef_contribution
from hn_contributions.contributions
where materiau_objet='$clef_materiau'
and ( type='transcription linearise'
or type='transcription diplomatique' )
$suffix
order by date_disponibilite_online", $connection);
while ($rec = mysql_fetch_array($result))
{
ref_contribution( $rec['clef_contribution'],
$src_img,
$href_base,
$href_base_auteur
);
}
mysql_close($connection);
}
Expansions multiples
L’informatique vit d’un processus continu et irréfrénable de création de couches d’abstraction successives qui, à partir d’éléments simples, donne naissance à des outils de plus en plus puissants et sophistiqués. Notre système n’échappe pas à cette règle générale et, en conclusion de notre article, nous en donnerons quelques exemples qui touchent aux langages utilisés, à la structure d’ensemble du système informatique et à l’envergure du projet lui-même et à ses possibilités d’expansion.
Dépasser les limites des outils disponibles
Disposer d’un langage puissant tel que PHP permet de contourner certaines limitations de notre serveur de base de données MySQL. Nous avons en effet la possibilité d’étendre le dialecte SQL utilisé par le serveur grâce à des fonctions PHP capables d’interpréter le langage étendu. Ces fonctions prendront en argument une requête dans le langage étendu et l’interpréteront en exécutant un certain nombre de requêtes SQL standard, en traitant les résultats et en composant finalement la réponse à la requête initiale.
Par exemple, la construction syntaxique des selects imbriquées n’est pas possible dans le dialecte de MySQL. Ou encore, le système ne permet pas de définir des vues (views), c’est-à-dire des tables virtuelles calculées dynamiquement à partir des tables composant réellement la base de données. Or, cette dernière possibilité est très utile dans un projet comme le nôtre, où les données sont forcément distribuées de façon complexe sur plusieurs tables et sur plusieurs bases. Les vues nous permettraient de définir une fois pour toute une certaine façon de composer les données provenant de plusieurs tables, ce qui simplifierait énormément l'écriture des requêtes.
Par exemple, dans le cas où il serait nécessaire d’accéder aux informations concernant un essai critique publié dans l’HyperNietzsche, il faudrait accéder à la table des auteurs pour récupérer le code de l’auteur, à la table des données personnelles pour récupérer son nom et prénom, à la table des entrées bibliographiques pour récupérer le titre et la date de publication de l’essai et à la table d’allocation des fichiers pour récupérer l’adresse du fichier contenant le texte de l’essai. Si au contraire nous avions défini préalablement (avec une instruction select) une vue comportant la référence complète d’un essai, il nous suffirait d’accéder à une seule table virtuelle (la vue en question) avec une select très simple au lieu de devoir écrire une select complexe accédant aux différentes tables concernées.
Un interpréteur capable de gérer les vues et les selects imbriquées a pu être écrit sans grand effort en PHP grâce à la riche librairie de fonctions standard pour la manipulation des chaînes de caractères. Les vues sont mémorisées dans la table views de la base hn_meta. Une nouvelle fonction d'envoi de requêtes au serveur MySQL, mysql_equery() (equery pour extended query), remplace la fonction standard mysql_query(). La syntaxe d'une select de MySQL s'ecrit, d'une façon quelque peu informelle, de la façon suivante :
<Select> ::= select <Columns> from <Tables> [ where ... ]
<Tables> ::= <Table> [ as <Id> ] | <Table> , <Tables>
<Table> ::= <Id>
Or, dans la syntaxe étendue, la table peut être une vue, identifiée par un nom, ou peut être le résultat d'une sous-select (select imbriquées) définie à l'intérieur des doubles crochets.
<Table> ::= <Id> | view(<Id>) | [[ <Select> ]]
Il faut remarquer le caractère récursif de la syntaxe : la sous-select et la définition de la vue peuvent appartenir elles aussi au langage étendu. Par exemple, nous pourrons inclure dans notre code PHP des appels du genre :
$result = mysql_equery("select clef, titre, auteur
from view(essais), $connection);
La fonction mysql_equery() récupèrera la définition correspondante à l'identificateur essais dans la table hn_meta.views. Il s'agira peut-être d'une select imbriquée, comme par exemple :
select clef_contribution as clef, date_publication, titre, auteur
from [[ select *
from hn_contributions.contributions
where type_contribution = 'essai']]
Parallélisation du système
Actuellement le système HyperNietzsche tourne sur un PC compatible d’entrée de gamme qui nous a servi dans la phase de construction du site et qui devrait gérer sans trop de problème le trafic occasionné par son lancement.
Mais, lorsque cette solution se révèlera insuffisante pour un nombre plus important d’accès simultanés, nous n’aurons pas besoin de changer la structure de la base de données, ni de réécrire le code PHP. Grâce, encore une fois, à la disponibilité de logiciels libres d’excellente qualité, comme OcamlP3L basé sur MPI ou PVM (Parallel Virtual Machine), il ne sera ni coûteux ni compliqué de mettre en place un système distribué de gestion des requêtes provenant d’Internet, en ajoutant autant de machines que nécessaire.
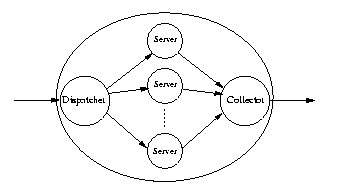
Pour augmenter les performances du système, les bases de données et les fichiers de l’HyperNietzsche pourraient êtres répliqués totalement ou en partie sur chaque ordinateur serveur de requêtes, une redondance des données qui pourrait également être utile comme élément de tolérance aux pannes.
Distribuer les requêtes adressées à un serveur Web sur plusieurs serveurs est un problème pour lequel sont envisageables différentes solutions. La question principale est celle de cerner les goulets d’étranglement possibles, du côté du réseau ou alors du point de vue de la répartition de tâches ou encore de l’allocation des fichiers. Nous ne présenterons pas ici une liste des solutions possibles et, d’ailleurs, sur ce point spécifique nous n’avons pas encore tranché en faveur d’une solution déterminée car pour l’instant nous ne sommes pas en mesure d’estimer la quantité et la nature des requêtes qui afflueront vers le système.
Mais sans besoin de recourir à des logiciels spécifiques, les outils que nous avons choisis, PHP et MySQL, nous permettent d’envisager une solution simple et à portée de main. Elle consiste à utiliser plusieurs machines comme serveurs de base de données, chacune avec une copie de la base HyperNietzsche, et à prévoir une politique simple (par exemple un choix au hasard) que les fonctions PHP adopteront pour distribuer les requêtes SQL sur les serveurs. En effet, le serveur Apache peut, par le biais de la fonction standard de PHP mysql_connect(), se connecter à n’importe quel serveur MySQL sur le réseau local ou sur l'Internet.
Imaginons que notre serveur Apache tourne sur une machine appelée local.net.fr. Voici un exemple de code PHP qui établit une connexion avec un serveur MySQL résident à l'adresse remote.net.fr et lui demande la liste des bases de données qu'il contient.
<html>
<head>
<title>Bases de Données du serveur MySQL@remote.net.fr</title>
</head>
<body>
<?
$connection = mysql_connect("remote.net.fr","apache","secret");
$result = mysql_query("show databases", $connection);
while ($rec = mysql_fetch_array($result)) { echo $rec[0],"<BR>"; }
mysql_close($connection);
?>
</body>
</html>
Pour que le serveur MySQL de remote.net.fr accepte la connexion et réponde à la requête "show databases", il devra être configuré pour autoriser les accès de l'utilisateur apache provenant de la machine local.net.fr et ayant le mot de passe "secret".
Revenons sur le schéma classique de répartition des tâches de la figure précédente. Les rôles de dispatcher et de collector seraient ici assurés par le serveur Apache interprétant le code PHP, tandis que les serveurs seraient des serveurs MySQL résidents sur des machines distinctes et les communications seraient basées sur le protocole standard TCP/IP.
MetaHyper
Le système HyperNietzsche que nous présentons ici a l'ambition de valoir en tant que modèle utilisable pour d'autres auteurs ou pour des problématiques philosophiques ou littéraires susceptibles d'être traitées dans un contexte de collaboration internationale entre chercheurs.
Si le système HyperNietzsche se généralisait à d'autres auteurs, nous pourrions envisager encore une autre montée dans le processus d'abstraction. L'idée serait d'avoir des systèmes, que nous appellerons « MetaHyper », qui regroupent les informations provenant de différents systèmes de base suivant le modèle HyperNietzsche. Un MetaHyper pourrait interroger les bases de données des systèmes de type Hyper (HyperSchopenhauer, HyperKant, HyperDescartes) et se proposer comme un site de discussion théorique, par exemple, sur l'idée de sujet de la connaissance.
Mais comment le réaliser techniquement ? En ce cas, la philosophie générale qui guide notre démarche, l'Open Source, se révèle particulièrement précieuse et même la seule utilisable. En effet, nous avons vu dans le paragraphe précédent que le serveur de base de données peut résider ailleurs que le serveur http, n'importe où sur l'Internet et donc également sur un autre site Hyper. Nous avons vu qu'il suffit que ce dernier nous donne le droit d'accès pour pouvoir interroger la base à distance. Mais, bien entendu, cela ne n'est pas suffisant. Pour que l'interrogation d'un serveur distant donne les résultats escomptés, il nous faudra connaître dans les détails la structure des bases de données distantes. Autrement dit, ces structures devront êtres publiques ou Open Source.
<html>
<head>
<title>Interrogation du serveur postgreSQL@HyperKant.net</title>
</head>
<body>
<?
$connection = postgreSQL_connect("HyperKant.net","apache","secret");
$result = postgreSQL_query("select * from hk.oeuvres", $connection);
…
mysql_close($connection);
?>
</body>
</html>
Dans cet exemple, le serveur Apache de notre MetaHyper interroge à distance un serveur de base de données postgreSQL résidant sur le système HyperKant.net. La requête envoyée au serveur postgreSQL présuppose l'existence d'une base de données dénommée hk contenant une table dénommée œuvres.
Bibliographie
Unix & Réseau
1) Craig Hunt. TCP/IP Administration de réseau. Deuxième édition. Éditions O'REILLY, 1998.
2) Christian Pélissier. Utilisation Administration système et réseau. 2e édition. Hermès, 1996.
Bases de Données
3) Georges Gardarin. Bases de Données objet & relationnel. Éditions Eyrolles, 1999.
Linux
4) Rémi Card, Eric Dumas, Franck Mével. Programmation Linux 2.0, API système et fonctionnement du noyau. 2e édition. Éditions Eyrolles, 1998.
5) Matt Welsh. Linux Installation & Getting Started. Linux Documentation Project (LDP), 1998. Original et traductions disponibles à l'adresse http://www.linuxdoc.org.
6) Kurt Seifried. Linux Administrator's Security Guide. Linux Documentation Project (LDP), 2000. Original et traductions disponibles à l'adresse http://www.linuxdoc.org.
7) Lars Wirzenius, Joanna Oja. The Linux System Administrators' Guide. Linux Documentation Project (LDP), 1999. Original et traductions disponibles à l'adresse http://www.linuxdoc.org.
8) Olaf Kirch. The Linux Network Administrators' Guide. Linux Documentation Project (LDP), 1996. Original et traductions disponibles à l'adresse http://www.linuxdoc.org.
9) Larry Greenfield. The Linux Users' Guide. Linux Documentation Project (LDP), 1996. Original et traductions disponibles à l'adresse http://www.linuxdoc.org.
Apache et PHP
10) Ben Laurie, Peter Laurie. Apache. Installation et mise en oeuvre. Éditions O'REILLY, 1998.
11) Leon Atkinson. Core PHP Programming. Prentice Hall PTR, 1999.
12) Bakken, Aulbach, Schmid, Winstead, Wilson, Lerdof, Suraski. PHP3 Manual. Stig Saether Bakken, 1998. Disponible à l'adresse http://www.php.com.
13) Philippe Chaléat, Daniel Charnay. Programmation HTML et Javascript. Éditions Eyrolles, 1998.
14) Christian Neuss, Johan Vromans. Applications CGI en Perl pour les Webmasters. International Thomson Publishing France, 1996.